我的研究项目
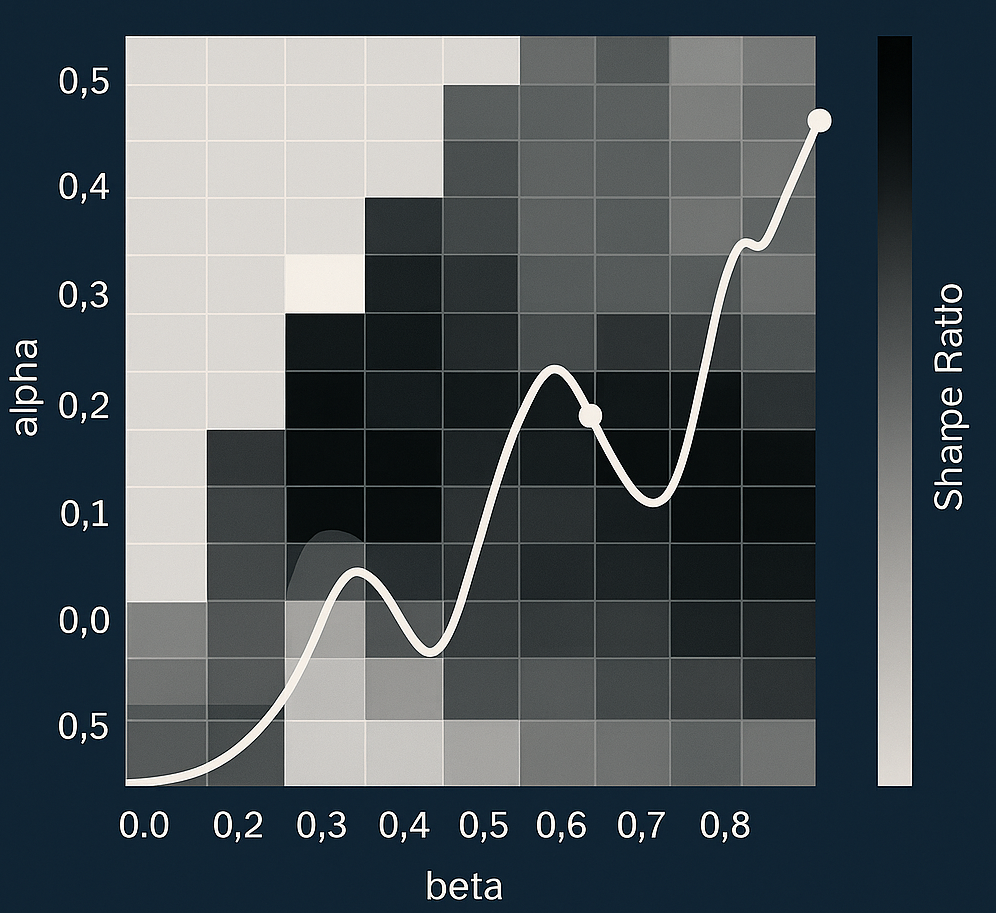
一个完全可复现的量化研究项目,围绕 USD/CAD 汇率趋势持续性,构建基于双指数平滑(Dual ES)的完整预测与交易流水线:
信号工程、α–β 参数调优、多空非对称性检验、缓冲区与减速退出实验、回测评估、夏普比率测算以及逐笔交易级准确率分析。
项目系统呈现了我在 量化分析、数据科学工作流设计、数学建模、统计推断与技术沟通 方面的能力。
📌 项目总结
目标: 为 USD/CAD 构建一个基于双指数平滑(ESα, ESβ)的趋势跟随交易系统,并评估多空对称性、参数敏感性及退出逻辑。
方法与流水线:
- 基于 α < β 的双 ES 交叉趋势信号
- 对 α、β 进行网格搜索与稳健性分析
- 分别评估多头 / 空头策略的最优参数与表现差异
- 设计并测试“价格距离缓冲区”“动量减速退出”等退出机制
- 以逐笔交易为单位汇总收益、胜率与回撤,而不仅是日度收益
关键结果:
- 最优参数:
α = 0.20,β = 0.60 - 策略夏普比率从 0.26 提升至 0.45
- 逐笔交易胜率约 73%
- 引入距离缓冲与减速退出后,整体收益和风险调整表现 反而下降
展现能力:
- 以研究思维搭建完整量化策略生命周期(信号 → 参数 → 回测 → 诊断)
- 不只看“好看曲线”,而是关注稳健性、解释性和可推广性
- 能将技术细节整理成面向 PM / 风控 / 同行研究者的清晰报告
完整技术报告见下方嵌入文档。
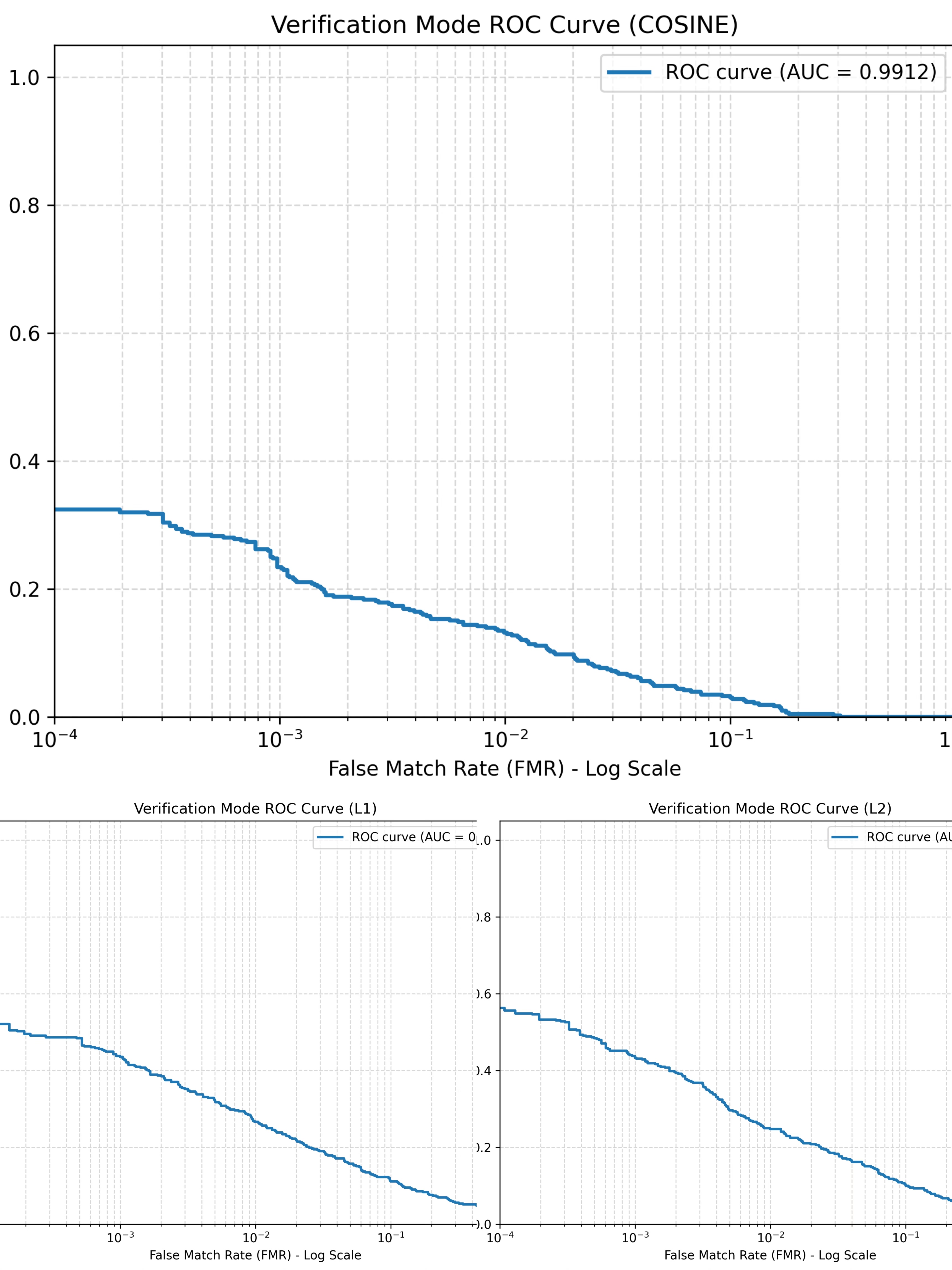
一个基于经典论文方法实现的完整计算机视觉与模式识别项目,作为哥伦比亚大学课程项目完成。
项目围绕虹膜生物识别任务,搭建了从原始眼部图像到最终识别结果的完整流水线,包括虹膜定位、归一化、图像增强、手工特征提取、PCA + Fisher 线性判别匹配,以及识别与验证评估。
项目系统展现了我在 计算机视觉、机器学习系统设计、数学建模、实验调试、指标评估与技术实现 方面的能力。
📌 项目总结
目标: 基于 Ma et al. (2003) 的经典方法,在 CASIA-IrisV1 数据集上实现一个完整的虹膜识别系统,并在固定训练/测试协议下完成识别与验证评估。
方法与流水线:
- 使用投影极小值、阈值分割、轮廓分析与 Hough Circle 进行虹膜与瞳孔定位
- 基于非同心 rubber-sheet 模型,将虹膜区域归一化为固定大小的矩形表示
- 通过背景光照校正与局部直方图均衡化提升纹理可见性
- 使用两个 circularly symmetric spatial filters 提取虹膜纹理响应
- 基于 8×8 block 的 Mean + Average Absolute Deviation 构建 1536 维特征向量
- 结合 PCA + Fisher Linear Discriminant (FLD) 进行降维
- 采用多模板最近中心匹配,并比较 L1、L2、Cosine 三种距离度量
- 通过 CRR 与 Verification ROC 曲线评估系统性能
我解决了什么问题:
- 将原始灰度眼部图像转化为一个可复现的完整识别流水线,而不只是单一步骤分类器
- 通过归一化与旋转模板匹配,处理了几何变化和角度偏移问题
- 通过图像增强和局部块统计特征,降低了亮度不均与局部噪声带来的干扰
- 通过多轮调试 ROI、匹配策略和评估协议,使实现更贴近论文和课程要求,并显著提升最终识别效果
关键结果:
- Original Space CRR:L1 = 73.38%,L2 = 71.99%,Cosine = 73.38%
- Reduced Space CRR:L1 = 80.79%,L2 = 81.25%,Cosine = 86.11%
- Verification ROC AUC:L1 = 0.9476,L2 = 0.9555,Cosine = 0.9912
- 降维后的匹配空间相比原始特征空间明显提升了识别性能
- Cosine 距离在最终识别与验证结果中表现最好
展现能力:
- 能够从原始图像出发,搭建完整的计算机视觉 / 机器学习识别系统
- 能够根据实验结果迭代调试,而不是只停留在“代码能跑”层面
- 能够将论文方法转化为模块化、可复现的工程实现
- 熟悉经典机器学习、特征工程、降维与指标分析
- 具备将复杂技术流程整理为清晰项目结构与技术文档的能力
本项目作为哥伦比亚大学课程项目完成,重点体现了从论文实现、系统搭建到性能优化的完整技术过程。
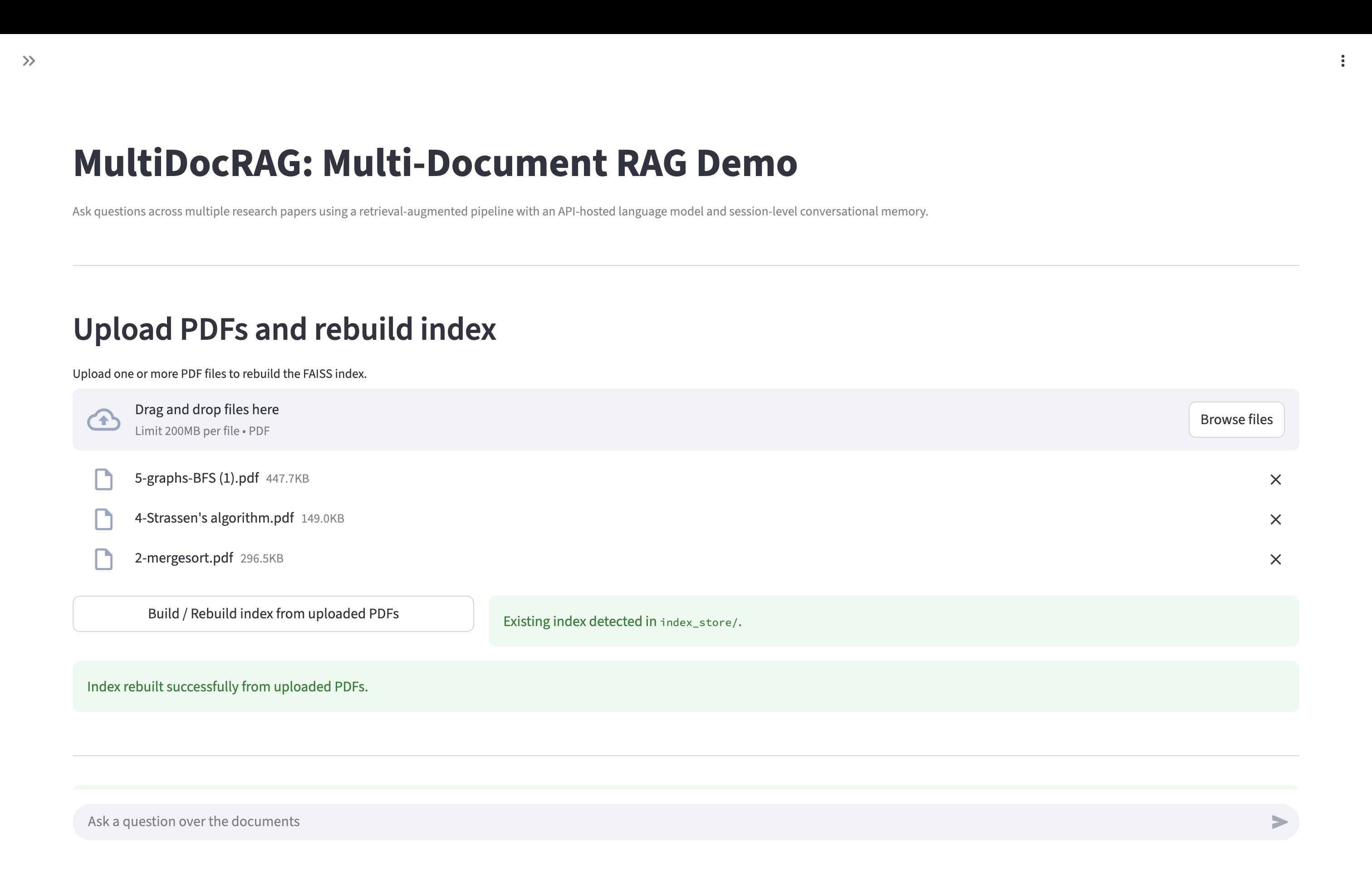
一个面向多文档场景的全栈检索增强生成(RAG)系统,可对多份上传 PDF 进行跨文档推理。 系统支持可扩展的文档摄入、语义分块、向量检索、透明的证据展示以及自动化评估框架。 本项目体现了我在 LLM 工程、应用机器学习、数据管道设计、评估方法论以及端到端产品原型设计 方面的能力。
📌 项目总结
目标: 构建一个可以进行跨文档综合的 AI 助手,以多份 PDF 为知识源,给出有证据支撑且可追溯的回答。
系统设计:
- 多 PDF 文档上传、清洗与规范化处理
- 滑窗式语义分块 + 重叠区设计,避免上下文割裂
- 基于 Sentence-Transformers 的向量嵌入,使用 FAISS 进行高效检索
- 检索结果带相似度得分与原文片段,支持用户检查证据
- LLM 推理层采用“有证据生成 + 安全拒答”策略,避免胡编乱造
- 自动评估框架,从正确性、证据支撑和拒答安全性三个维度打分
- 基于 Streamlit 的 Demo 页面,支持上传文件、查看检索结果及完整提示词
应用场景:
- 科研与政策报告的跨文档信息整合与对比
- 商业 / 行业情报分析(多国法规、多家机构报告并行)
- 大型技术文档与 API 文档的问答系统
- 自动化文献综述与综述草稿生成
我在项目中的能力体现:
- 从零设计并落地完整 ML / LLM 系统,而不仅是单一模型
- 对数据工程链路(清洗 → 分块 → 嵌入 → 检索)的细节有实战经验
- 能主动设计评估方法而不是只凭“感觉好用”
- 具备将技术系统包装成对用户友好的工具 / 产品原型的能力
当前进展:
- 文档摄入、语义分块与向量检索模块已稳定运行
- LLM 推理模块已接入记忆与拒答逻辑
- 基于 27 个问题的自动评测数据集已完成并跑通
- Demo 已部署在 HuggingFace Spaces,完整报告可下载
项目仍在持续迭代中,包括 rerank 策略、模型替换与失败案例系统分析等。
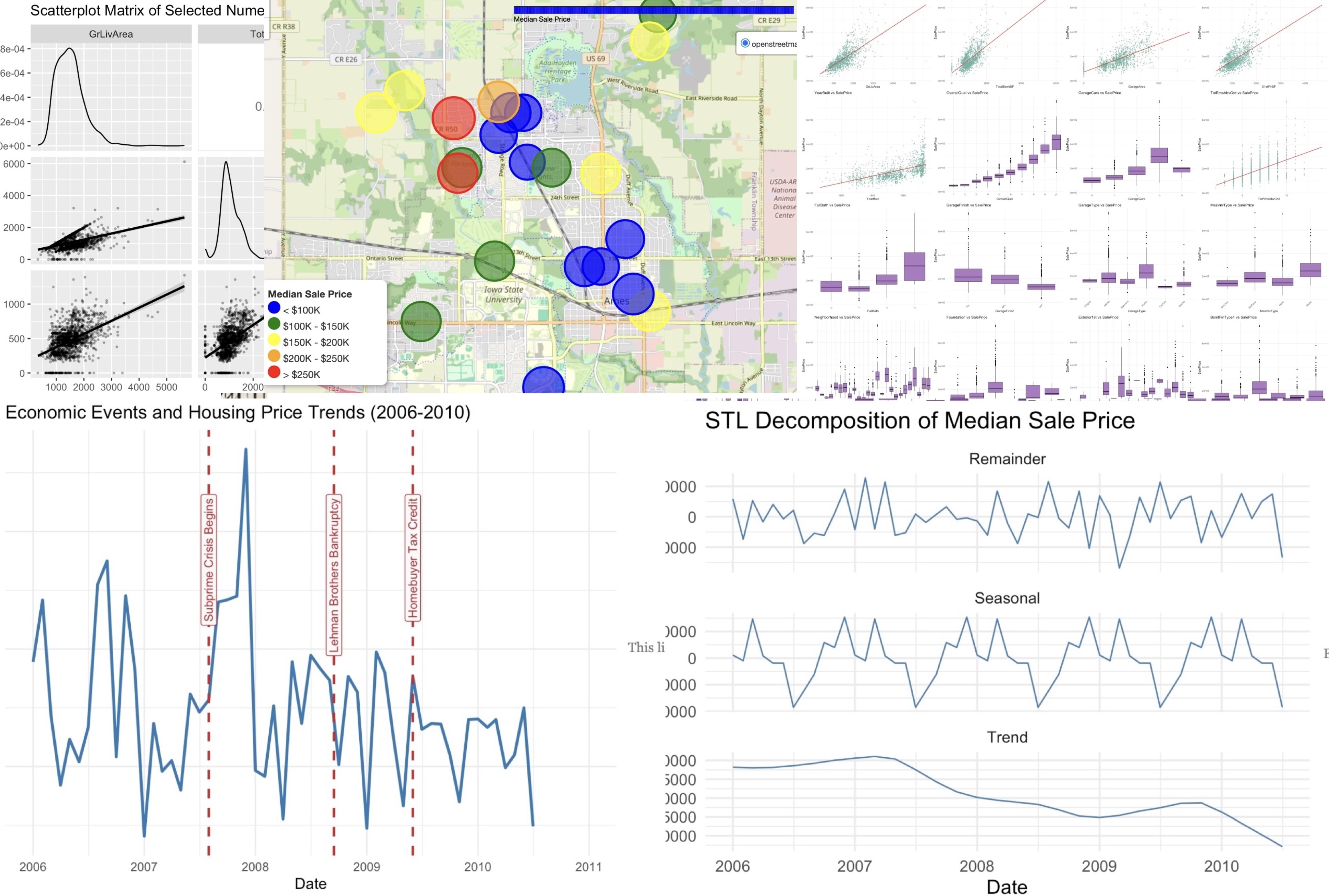
基于 Ames 房价数据构建完整预测流水线:从探索性数据分析、特征工程,到岭回归、LASSO、随机森林、Group LASSO 等多种模型。
在获得较强预测精度的同时,更关注于回答一个现实问题:到底是什么在驱动房价?
项目强调模型的可解释性与面向非技术决策者的沟通,将高维数据转化为开发商、购房者、银行等可以直接使用的决策信息。
📌 项目总结
目标: 不仅仅是训练一个“准确”的房价模型,而是构建一个可解释的房产分析流水线,清晰识别驱动价值的经济因素。
方法: 以 80+ 变量的 Ames 数据为起点,主要步骤包括:
- 区分 数值型 / 分类型 自变量,并对
OverallQual、MoSold等变量进行有序重编码 - 通过 相关性 + 效应量(η²) 评估变量重要性
- 利用 调整后 GVIF 控制多重共线性
- 构建岭回归、LASSO、随机森林与 Group LASSO 等模型进行对比
- 制作热力图、社区地图、STL 趋势分解等可视化用于结果解释
关键发现:
- 面积与建造质量是核心价值驱动因素(如
GrLivArea、TotalBsmtSF、OverallQual) - 在控制房屋属性后,社区 / 邻里效应仍然显著存在
- 车库配置、外立面材质等形成第二梯队但仍重要的增值因素
- 时间结构与宏观事件高度相关,例如次贷危机与税收激励时期的价格波动
能力体现:
- 能够将原始市政/交易数据清理并转化为可用于决策的分析结果
- 贯通 EDA → 特征工程 → 建模 → 可视化解释 → 业务沟通 的完整链路
- 方法论可平移至定价、风险建模与其他应用型分析场景
完整交互式分析见下方 HTML 报告。
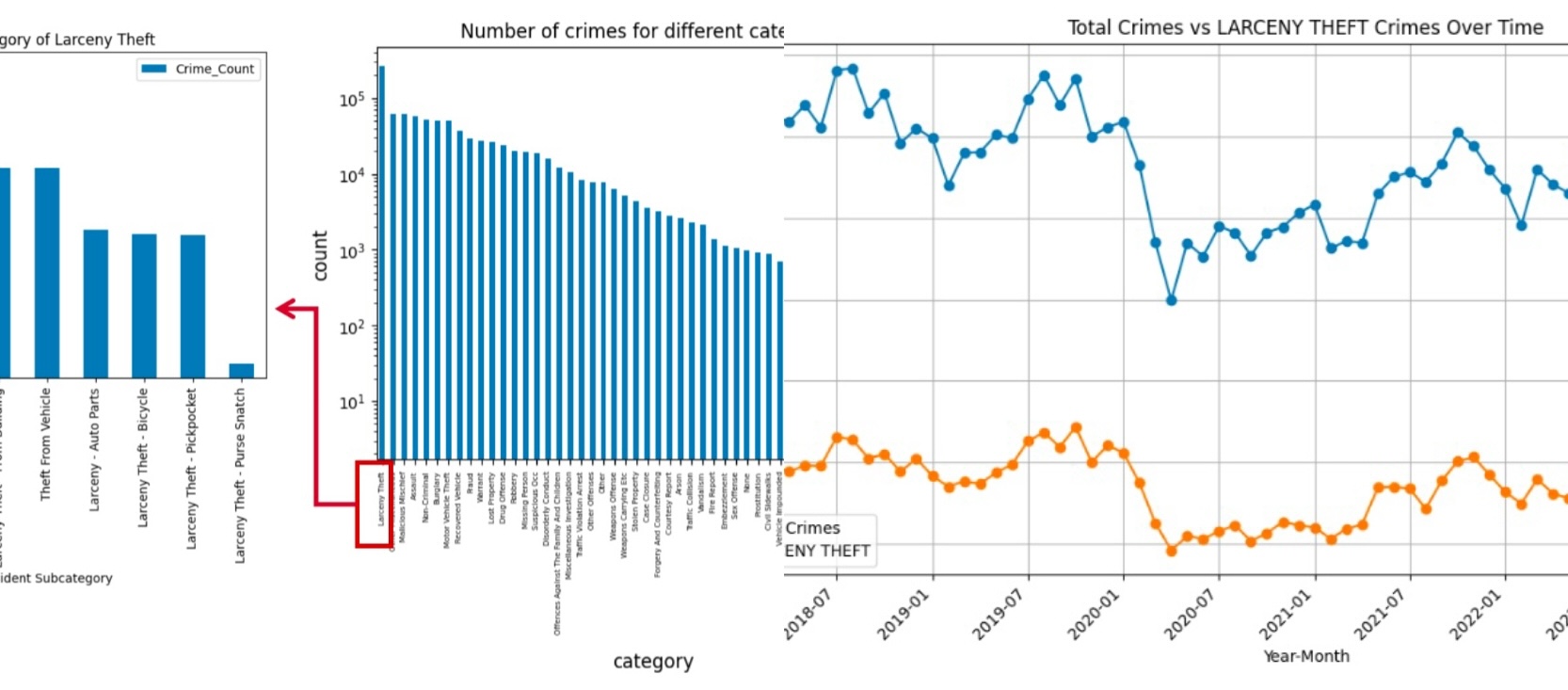
构建覆盖 90 万+ 警情记录与 ACS 社会经济数据的大规模空间计量经济学分析流水线,将 SF 警方案件数据与普查局分区面板数据进行整合。
通过固定效应逻辑回归、Poisson / 负二项计数模型以及时间序列预测,定量刻画收入不平等、失业率与流动性模式如何影响犯罪趋势。
项目展示了我在 因果推断、纵向面板建模、数据整合与政策分析 方面的能力,这些方法亦可迁移至商业预测与复杂系统建模。
📌 项目总结
目标: 定量评估犯罪模式是否由经济因素驱动,例如收入不平等、失业率、通勤方式与人口结构变化等。
数据与流水线:
- 将 913,732 条案件级犯罪记录与 2017–2022 年 ACS 社区级社会经济数据进行空间匹配与面板构建
- 面板结构:census tract × 年度
- 模型:固定效应逻辑回归(个体级)、Poisson / 负二项(区级计数)
- 时间序列预测:ARIMAX / SARIMAX,捕捉经济与季节性因素
- 构造经济指标增量与流动性特征(公共交通使用率、通勤方式等)
主要结论:
- 公共交通与骑行比例越高的区域,多个犯罪类别的发生率持续上升
- 在控制空间与人口密度后,收入不平等与失业率对犯罪的影响呈现反直觉的负相关,提示存在较强城市结构混淆
- 本科及以上教育占比提升会降低暴力与治安类犯罪,但与财产犯罪存在正向关联
- 疫情期间:公共秩序类犯罪下降,财产类犯罪上升,反映线下活动与居家模式的改变
方法论启示(可迁移性):
- 面板模型相对个体模型在结构解释上更稳健,这一点对商业与运营场景同样重要
- 在存在过度离散时,负二项模型显著优于 Poisson,这一逻辑可直接用于运营指标与需求预测
- 流动性与密度往往比单纯的收入/失业等经济指标更具预测力
完整模型设定与回归表见下方报告。

一个完全手写的单页微型网站,将日式插花课程作品集转化为一个沉浸式数字体验。
整站不依赖框架,从布局、动画到交互与背景音乐均由我独立设计与实现。
项目展示了我在 前端工程、交互设计、信息层级与体验「最后一公里」 等方面的关注,而不仅是静态页面堆叠。
📌 项目总结
目标: 设计并实现一个小而完整的 Web 体验,用流畅的过渡、响应式布局与环境音效,让插花作品像一个“被精心陈列的产品”,而非普通代码作业。
实现内容:
- 从零搭建的响应式单页网站,适配多终端与深浅色环境
- 完全基于 CSS 的动画系统(进入动效、悬停反馈、文本渐显),不依赖外部动画库
- JavaScript 控制导航、滚动效果与 HTML5 音频播放,实现视听联动
- 布局上平衡摄影、文字与留白,使整体更像策展叙事而非单纯技术展示
与我其他工作的关联:
- 证明我可以从 概念 → 体验结构 → 视觉 → 代码实现 全流程独立推进
- 很多设计思路可直接复用到分析看板、内部工具、业务可视化界面上
- 体现我对“数据/模型如何被人真正感知和使用”的重视,而不是停在模型本身
下方为网站部分截图,实际体验可访问 Demo 链接。



